chapter 2 歴史データをつなぐこと −目録データ−(山田太造)★『歴史情報学の教科書』全文公開

chapter2
歴史データをつなぐこと
−目録データ−
山田太造(東京大学史料編纂所)
1. はじめに
大辞泉によれば、目録とは「書物の内容の見出しをまとめて記録したもの」、または「所蔵・展示などされている品目を整理して書き並べたもの」と説明されています。前者は書物の目次、後者はカタログに相当すると考えられます。書物の目次は文章の見出しだけではなく、文章へアクセスするための手段としても利用することができます。カタログにはその中に書かれている品目を一覧する役割も担っています。つまり、目録は記されている内容を識別し、それぞれに対してアクセスする手段を提供しています。これは目録に示されているモノが何であっても変わることはないと考えられます。
さて、ここでは目録の対象として歴史データを考えます。歴史データといっても、古文書・古記録のような文献資料もあれば、刀剣や鎧といった武具を含むモノ資料もあります。また「織田信長」「坂本龍馬」といった人名、「下総国印旛郡」のような地名、「文久3年3月7日」のような日付なども歴史データとして位置づけられます。文献資料ですと、その内容、つまりは本文も歴史データになりますし、書かれた文字も歴史データになります。昨今では画像・音声・動画を含むデジタルデータも歴史データとして扱われます。このように多様な歴史データが存在します。これらの歴史データにアクセスできる手段として目録があるとも考えることができます。
2. 目録を整理していく
扱うモノを登録していくことで目録が作成されていきます。ただし、無秩序に登録していくと扱いづらくなります。例えば、探したいものがあるかどうかを確かめたい場合、登録された内容を1件ずつ確認していくのは非常に効率が悪いです。また、ほかのモノとの違いがわからないと扱いづらくなります。さらに、目録の対象となっているモノにアクセスできる状態になっている必要があります。そのため、管理の実態に合わせて目録を作成していくことが必要です。モノを分類するなど整理しておき、その整理状況に応じて目録を作成していくことになります。同じ性格の書物を近くに配置したり、目的に応じてフォルダを作成してファイルを配置したりと、皆さんの書棚の整理やPC内のファイル整理と同様です。
これは歴史データでも変わることはありません。対象を整理し、その整理の実態に応じて目録を作成していきます。これ以降、東京大学史料編纂所における歴史データを例に説明していきます。
3. 東京大学史料編纂所所蔵史料
東京大学史料編纂所(以下、史料編纂所)は、日本の古代から明治維新期に至る前近代の日本史に関係する歴史資料(以下、史料)を研究する大学附置研究所です。史料の調査、収集および分析を行い、『大日本史料』『大日本古文書』『大日本古記録』といった日本史の基幹となる史料集を編纂・公開しています。史料編纂所では、『大日本史料』のような事件が起きた時間の流れに沿って関連史料を集める編年史料と、『大日本古文書』や『大日本古記録』のような史料群の構成と内容を精密に復元する編年史料のふたつの編纂を行っています。史料集の編纂・公開は1901年に『大日本史料』6編1(1333年、建武の新政開始)、『大日本史料』12編1(1603年、江戸幕府開府)、『大日本古記録』編年文書(702年以降の編年古文書集)の3冊を出版して以降、現在まで120年近く継続しており、1100冊以上の刊行に至りました。
史料研究および史料集編纂を支えるためには、史料そのものが必要です。日本史史料は日本だけでなく海外にも所在しています。史料編纂所では、日本全国・世界各地に史料調査に出掛け、注目すべき史料について複製を行い、史料集編纂のための素材となる史料を収集してきました。このような作業を史料採訪と呼んでいます。史料編纂所の発足当初より、影写(敷き写し)、謄写(見取り写し)、模写という技術を用いて収集を行ってきました。1970年以降からはマイクロカメラによる撮影、2010年以降はデジタルカメラを用いた撮影により収集を行っています。さらに、寄贈・移管・購入などによって受け入れた多数の原本・写本類を所蔵しています。国宝・重要文化財に指定されたものや、まとまって伝来した史料群(特殊蒐書)など多くの貴重書もあります。図1は史料編纂所が築き上げた日本史史料コレクションの概要を示しています。
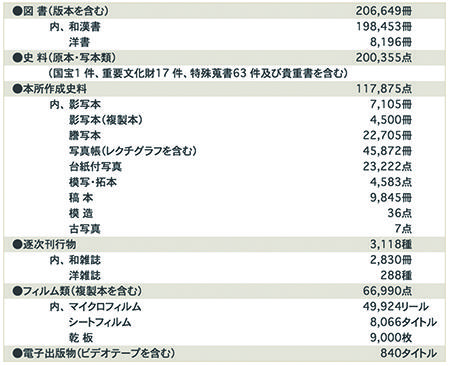
図1 東京大学史料編纂所所蔵史料概要(2016年3月31日時点)
4. 史料を分類していく
膨大な日本史史料コレクションを築き上げた結果、史料を1列に並べる、または書架などに単に配置していくだけでは管理しきれなくなりました。そのため体系的な分類が必要になりました。
図書の世界では、図書の主題や内容に基づいて分類するための図書分類法が存在します。国際十進分類法(Universal Decimal Classification; UDC)、デューイ十進分類法(Dewey Decimal Classification; DDC)などがあり、特に日本では日本十進分類法(Nippon Decimal Classification; NDC)や国立国会図書館分類表(National Diet Library Classification; NDLC)などが利用されることが多いです。
史料編纂所の日本史史料コレクションは史料編纂所図書室にて管理されています。図書室ですので図書分類法を用いて管理したいのですが、歴史、しかも日本史に偏ってしまうため、これらの図書分類法をそのまま用いることができません。そこで、十進分類法での分類モデルをベースに史料編纂所における史料収集の活動に基づき史料を分類しました。この分類表を図2に示します。まずは原本史料かそうでないかで分けています。原本史料は区分000に分類されます。写本類は写本作成の手法によって影写本(史料区分300)・謄写本(史料区分200)・その他の写本(史料区分400)に分けられます。またマイクロフィルム、写真帳(史料区分610-630)、デジタル化された史料(史料区分B00、D00、D10およびD690)のように写真技術の手法に応じて分類します。史料採訪での撮影によるもの(史料区分M10)、海外関係のもの(史料区分690)、寄贈されたもの(史料区分M20およびM40)のようにマイクロフィルムの性格に応じて分類しています。所蔵史料のうち一括して伝来した史料・図書、あるいは内容に特色のある個人の蒐書などは"特殊蒐書"と呼んでおり、その史料群の体系をそのまま管理しています。例としては、国宝『島津家文書』(史料区分T18)や重要文化財『近藤重蔵関係史料』(史料区分T34)、『江戸幕府儒官林家関係史料』(T39)などがあります。

図2 東京大学史料編纂所所蔵史料の分類表
5. 目録を階層化していく
原本であっても一点ごとに古文書が管理されているものあれば、手鑑(古文書などを張った折本装の冊子)や巻子(いわゆる巻物)のように複数の古文書が含まれているものもあります。それらの一点ごとの古文書・手鑑・巻子などが箱に入っていたらその箱も管理の対象となります。Aという書架に配置されているBという箱のCという巻子にあるDという古文書、というのはよくある管理パターンです。この点でモノとして一般的な図書とは異なります。史料、というよりも実際には公文書などのいわゆるアーカイブの目録記述手法としてISAD(G)(General International Standard Archival Description)が国際アーカイブズ評議会(International Council on Archives)により策定され、その第2版であるISAD(G)2ndが国際標準として位置づけられています。ISAD(G)2ndでは目録階層を表現するためモデルとしてフォンド配置レベルモデル(Hierarchical model of the levels of arrangement for the fonds)が導入されています。このモデルでは、階層の上位から、フォンド(fonds)、シリーズ(series)、ファイル(file)、アイテム(item)があり、これらで史料目録が構成されます。フォンドは最上位に位置します。アーカイブの総体として位置づけられます。アイテムは管理上での最小単位です。シリーズとファイルは難しい概念です。一言でいうと、シリーズは団体などでのある活動により生じた史料全体、ファイルは扱う上での基本単位となります。フォンドとシリーズは目的などに応じてその下位階層としてサブフォンド(sub-fonds)、サブシリーズ(sub-series)を設けることができます。フォンドとファイルは必須ですが、シリーズとアイテムはなくても構いません。よってフォンドの直下にファイルを置くことが可能ですが、フォンドの直下にアイテムを置くことや、フォンドとシリーズのみで構成することはできません。
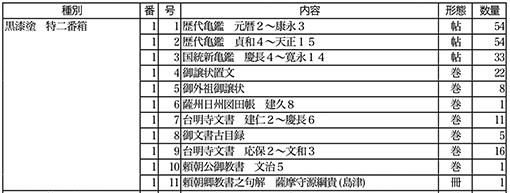
図3 島津家文書 黒漆特二番箱(T18-1)収載史料
史料編纂所蔵『島津家文書』を例にISAD(G)2ndに従った史料目録を見てみましょう。図3は島津家文書の黒漆塗特二番箱に関する目録です。黒漆塗特二番箱に歴代亀鑑(53通)と呼ばれる手鑑など11の史料があり、歴代亀鑑(53通)は元暦2年から康永3年の古文書53通(16番目の書状にはふたつの古文書が収載されていることから、古文書の点数としては図3に示す通り54点となることに注意)が収載され、そのひとつ目の古文書の名称が源頼朝下文です。この階層構造から、
・シリーズ:島津家文書
・サブシリーズ:黒漆塗特二番箱
・ファイル:歴代亀鑑(53通)
・アイテム:源頼朝下文
として目録を作成することができます。フォンドは史料編纂所所蔵史料になります。アイテムは最小の単位としての古文書1通を指し、それをファイリングしてある歴代亀鑑(53通)がファイルとなります。シリーズは島津家文書としてあります。これは先に述べた史料編纂所所蔵史料目録の分類表に基づいた区分に相当します。さらに階層ごとに識別できる番号を与えます。例えば、島津家文書はシリーズレベルでT18、黒漆塗特二番箱にはサブシリーズレベルで1、歴代亀鑑(53通)にはファイルレベルで1、源頼朝下文にはアイテムレベルで1を付与しています。よってここでの源頼朝下文には"T18-1-1-1"という識別子が与えられ、これにより史料編纂所所蔵史料全体の中からこの古文書にアクセスすることができます。また、歴代亀鑑(53通)の識別子は"T18-1-1"となります。このように管理している史料に対してアクセス手段(finding aid)を与えることがISAD(G)を用いる重要な理由と考えられます。このように史料編纂所では所蔵史料目録を階層化し、識別子を与えていくことで、所蔵史料目録データベース(Hi-CAT)を構築しています。
ISAD(G)2ndはアーカイブの階層化およびそれぞれの階層での記述項目をモデル化しています。データベースで検索し閲覧するために、実際に計算機で扱うためのデータとして記述していく必要があります。記述の国際標準としてはEAD(Encoded Archival Description)があります。2018年10月時点ではEAD3 Version 1.1.0がリリースされています。EAD3ではXML(Extensible Markup Language)による記述が可能です。EADを採用した国内の機関としては国立公文書館があります。
6. 目録を記述する
ここでは史料目録の記述について考えていきます。先にあげたように名称と識別子があります。ほかにはどのような項目があるでしょうか。ISAD(G)2ndでは記述要素は下記のように7つの領域に分けられています。
・識別領域(identity statement area):識別子(参照コード)、名称、日付など
・状況領域(context area):作者、履歴、管理情報など
・内容・構造領域(content and structure area):範囲、内容、配置情報など
・アクセス・利用条件領域(conditions of access and use area):アクセス条件、状態、言語、物理的特徴など
・関連史料領域(allied materials area):原本や写本の存在や所在、関連史料群など
・注釈領域(notes area):史料に対する注釈・備考・注記
・記述管理領域(description control area):アーキビストによる注釈・備考、記述自体の日付など
史料をアーカイブしていくためにはこれらの要素すべてを記述していくことは重要ですが、実際には難しい場合もあります。識別子、名称、配置情報などはアクセスしていくために必ず必要となりますし、管理していく上でも必須ですので、確実に記述することになります。物理的状態(数量,大きさ、重さなど)も記述しやすい項目です。しかしながら作者や日付はわからないことが多々あります。また内容に関わる記述は内容把握しなければ書きにくいです。また、典型的な古文書における宛所(いわゆる、宛先)のように、これらの以外の要素についても記述したいことがあります。一応、これらを備考として記述することもできますが、あくまでも備考であることから宛所として利用することは難しいかもしれません。また、年号がない、差出(古文書の作者)の名前が花押のみ、というように史料を深く読解しなければ記述できないことも多々あります。史料について把握し得る要素は史料によって、さらに所蔵しているところによって変わり得るため、確定的に設定することは大変難しいです。そのため実際には、対象である史料について、ISAD(G)の各項目をテンプレートとして利用し、拡張もしくはカスタマイズし、把握できるデータをできる限り記述していくことになります。
先にあげた『源頼朝下文』(T18-1-1-1)を例に目録データを見てみます。これは島津家文書-黒漆塗特二番箱-歴代亀鑑(53通)という階層構造であり、この階層構造はISAD(G)2ndに従って記述していくことができました。図4に示すように、各階層での記述もISAD(G)2ndの記述項目をカスタマイズして記述しています。これは東京大学史料編纂所データベース検索サービス(以下、SHIPS DB)における所蔵史料目録データベースに実際に格納されているデータです。

図4 源頼朝下文の史料目録データ
7. 記述要素を拡張していく
Web上で流通・共有していくことを目的とした語彙セットとしてDCMI Metadata Terms、いわゆるダブリンコア(Dublin Core)が有名です。DCMI Metadata TermsはDublin Core Metadata Initiativeにより提唱され、策定が進められてきました。最初にメタデータセット(Dublin Core Metadata Element Set)が策定されました。こちらはSimple Dublin Coreとも呼ばれ、15の要素(Title、Creator、Subject、Description、Publisher、Contributor、Date、Type、Format、Identifier、Source、Language、Relation、Coverage、Rights)から成り立ちます。その後、これらを含む55要素へ拡張したのがDCMI Metadata Termsです。ここでは単にDCと呼ぶことにします。
DCはISAD(G)2ndとは異なり、Web上でのデータ流通・共有を目的として設計されていますので、史料目録を記述するためだけに利用されるものではなく、さらに階層的に記述していくことを想定していません。また、その性格から、RDF(Resource Description Framework)と呼ばれるWeb上のデータ資源のメタデータを記述する仕組みによるデータモデルを用いた語彙セットでもあります。ISAD(G)2ndにおける各階層の要素記述においてDCも用いると記述自体やWeb上での流通が柔軟になっていくと考えられます。
また、人に関する語彙としてはFOAF(Friend of a Friend)、空間に関してはGeoNamesなどが有名です。RDFデータモデルによるデータ記述およびWeb上での流通方法についてはほかの章を参照してください。
8. 周囲の歴史データを関連付けていく
SHIPS DBは所蔵史料目録データベースを含め、史料目録、テキスト、図像、人名、地名、文字などを主題とした30のデータベースで構成されています。図5は下記のようにSHIPS DBから集めた『源頼朝下文』(T18-1-1-1)に関する歴史データを示します。

図5 多様な歴史データ
・所在・管理:これまでに説明しました所蔵史料目録データベースに格納されているデータ。
・一点目録:一点の古文書として記述した史料目録。この史料目録は大日本古文書ユニオンカタログにあるデータです。
・本文:この古文書は史料編纂所刊行の『大日本古文書』に収載されており、そこにある本文です。これは古文書フルテキストデータベースに格納されています。
・解題:この古文書の解題(解説文)。所蔵史料目録データベースに格納されています。
・索引・事項:大日本古文書ユニオンカタログや大日本史料総合データベース(索引)に格納されている人名、地名、事項名です。
・画像:この古文書の画像です。これは所蔵史料目録データベースから関連付けて管理しています。
・文字:電子くずし字字典データベースに格納されているデータ。
これらの関連データは史料そのもの、その史料を研究していく過程、その史料の研究結果として生じてきたデータです。そのデータを管理・利用していく上で、SHIPS DBでは史料目録データを利用しています。史料目録データと関連付けて管理していることにより、史料そのものへの参照が可能になり、それぞれのデータの根拠を示すことができます。それぞれのデータがどのような性格で、どのように管理・利用されていくか、についてはほかの章を参照してください。
9. おわりに
歴史学では史料の評価・検証、いわゆる史料批判、を根底としながら、そこから歴史的事実を追求していくための歴史像を見出だしていきます。そのため、史料を調査・収集し、関連する歴史データを検証していくことが重要です。その中でも史料目録データは歴史データの中心であり、基礎データの中の基礎データとして位置づけていくことができます。しかしながら、史料目録データも所在や配置場所の変更、さらには史料自体の研究が進んでいくことで、史料の年代や関連する人名などが変更したり、ほかの史料とくっつけて管理したり、ひとつの史料を分けて管理したりと、史料の管理方法が変わっていくこともあります。史料の現状を記述していくことも、もちろん重要です。本文、人名・地名といった事項、文字、画像などの多様な歴史データが関連付けられていることを考えますと、史料目録データが今後も永続的に利用されていく環境が必要です。これを考慮した史料目録データを作成していくことはかなり難しいです。さまざまな歴史データがあれど、史料目録データの記述が最も難しいかもしれません。また、さまざまな機関での史料目録データを統合的に検索していくプロジェクト、例えば人間文化研究機構nihuINTや国立国会図書館によるNDL Search、ではLinked Open Dataに代表されるセマンティックWeb技術を用いた横断検索を実現しています。しかしながら、史料そのものの管理体系は、残念ながら情報技術だけでは解決し得ない現状にあります。そのため史料や歴史の研究を進めていく中で、その成果を永続的に提供できる環境の整備は今後も不可欠だと考えられます。
─参考文献(Webページはいずれも2018-10-01参照)
『デジタル大辞泉』小学館, http://daijisen.jp/digital/index.html.
東京大学史料編纂所ウェブサイト, https://www.hi.u-tokyo.ac.jp/.
近藤成一「21万通の古文書を集める」、『歴史知識学ことはじめ』勉誠出版、2009年。
「史料編纂所の歴史とその課題」、東京大学史料編纂所編『歴史学と史料研究』山川出版社、2003年。
国際十進分類法, https://ja.wikipedia.org/wiki/国際十進分類法.
デューイ十進分類法, https://ja.wikipedia.org/wiki/デューイ十進分類法.
日本十進分類法, https://ja.wikipedia.org/wiki/日本十進分類法.
国立国会図書館分類表, https://ja.wikipedia.org/wiki/国立国会図書館分類表.
ISAD(G): General International Standard Archival Description - Second edition, https://www.ica.org/en/isadg-general-international-standard-archival-description-second-edition.
国文学研究資料館(アーカイブズ研究系)編『アーカイブズ情報の共有化に向けて』岩田書院、2010年。
山本博文, 東京大学史料編纂所所蔵島津家文書の情報化, http://www.tulips.tsukuba.ac.jp/limedio/dlam/B95/B952215/1/vol02/pdf/3401.pdf.
加藤友康, WWWサーバによる日本史データベースのマルチメディア化と公開に関する研究, 1999, http://www.hi.u-tokyo.ac.jp/personal/kato/index.htm.
EAD3, https://github.com/SAA-SDT/EAD3/tree/v1.1.0.
国立公文書館デジタルアーカイブについて, 国立公文書館, http://www.archives.go.jp/owning/d_archive/index.html.
Dublin Core Metadata Initiative, http://dublincore.org/.
Dublin Core, https://en.wikipedia.org/wiki/Dublin_Core.
FOAF, http://www.foaf-project.org/.
GeoNames, http://www.geonames.org/.
東京大学史料編纂所データベース検索サービス, https://wwwap.hi.u-tokyo.ac.jp/ships/shipscontroller.
Tim Berners-Lee, Linked Data - Design Issues, https://www.w3.org/DesignIssues/LinkedData.html.
Linked Data - Connect Distributed Data across the Web, http://linkeddata.org/.
nihuINT, https://int.nihu.jp/.
国立国会図書館サーチ(NDL Search), http://iss.ndl.go.jp/.
------
【全体目次】
ご挨拶○新たな学の創成に向けて(久留島 浩)
はじめに(後藤 真)
chapter1 人文情報学と歴史学
後藤 真(国立歴史民俗博物館)
chapter2 歴史データをつなぐこと―目録データ―
山田太造(東京大学史料編纂所)
chapter3 歴史データをつなぐこと―画像データ―
中村 覚(東京大学情報基盤センター)
●column.1 画像データの分析から歴史を探る―「武鑑全集」における「差読」の可能性―
北本朝展(ROIS-DS人文学オープンデータ共同利用センター/国立情報学研究所)
chapter4 歴史データをひらくこと―オープンデータ―
橋本雄太(国立歴史民俗博物館)
chapter5 歴史データをひらくこと―クラウドの可能性―
橋本雄太(国立歴史民俗博物館)
chapter6 歴史データはどのように使うのか―災害時の歴史文化資料と情報―
天野真志(国立歴史民俗博物館)
●column.2 歴史データにおける時空間情報の活用
関野 樹(国際日本文化研究センター)
chapter7 歴史データはどのように使うのか―博物館展示とデジタルデータ―
鈴木卓治(国立歴史民俗博物館)
chapter8 歴史データのさまざまな応用―Text Encoding Initiative の現在―
永崎研宣(人文情報学研究所)
chapter9 デジタルアーカイブの現在とデータ持続性
後藤 真(国立歴史民俗博物館)
●column.3 さわれる文化財レプリカとお身代わり仏像―3Dデータで歴史と信仰の継承を支える―
大河内智之(和歌山県立博物館)
chapter10 歴史情報学の未来
後藤 真(国立歴史民俗博物館)
おわりに